
Y’all know about n-grams, right? Wikipedia nails ’em:
… an n-gram is a contiguous sequence of n items from a given sequence of text or speech. The items can be phonemes, syllables, letters, words or base pairs according to the application. The n-grams typically are collected from a text or speech corpus.
So there you go.
Hmm, right …
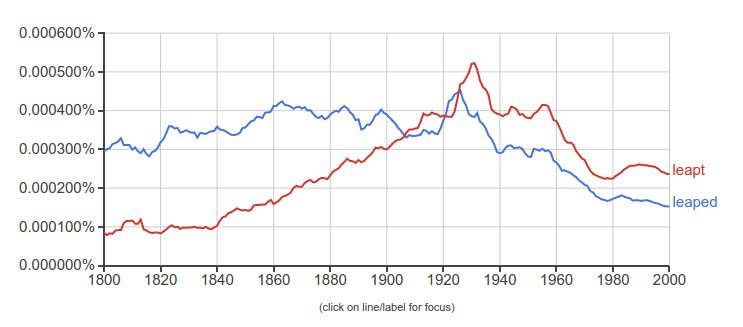
My introduction to n-grams came in the form of a question: which is used more, leaped or leapt (as in the past-participle of leap)? And the answer came back very quickly: both, depending on your market.
Google’s Ngram Viewer is the perfect tool for this sort of question. Simply input the two words separated by a comma, choose the years to search and corpus (the group of texts) you want to examine, and hit the Search Lots of Books button. Here’s my result for US English from 1800–2000:
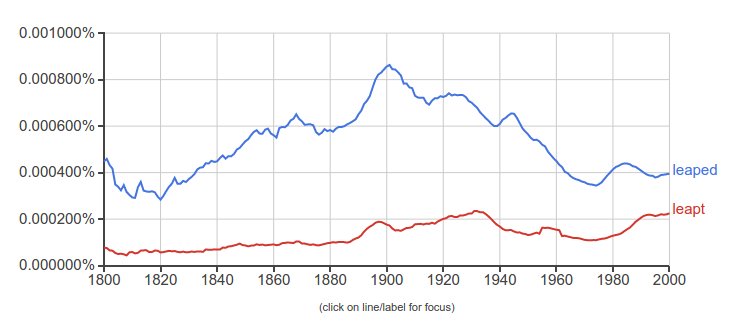
And British English for the same period:
So two winners, depending on your market.
Often there’s only one clear winner. When it was first published in 2011, a couple friends thought the title of my book Too Many Zeros was misspelt. Surely it should be Too Many Zeroes? Not according to Ngram Viewer, for American …
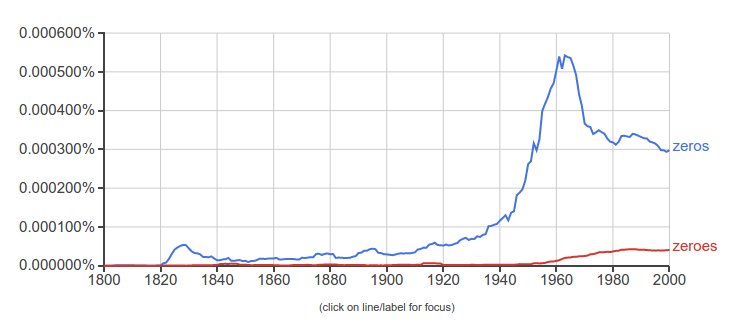
… or for British English …
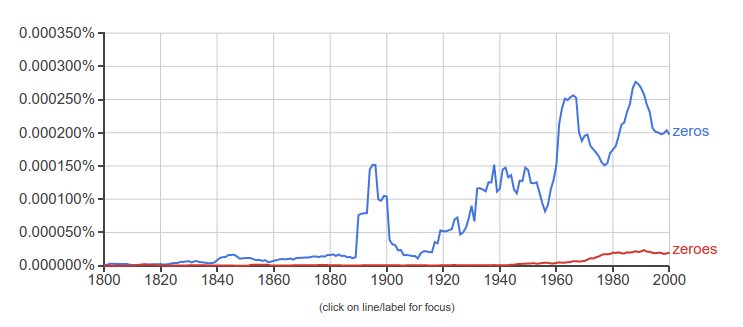
Of course, the answer you get will depend on the question you ask. The old GIGO principle — Garbage In, Garbage Out — applies. For example, if I add ones to my list of search terms, the book was hopelessly misnamed:
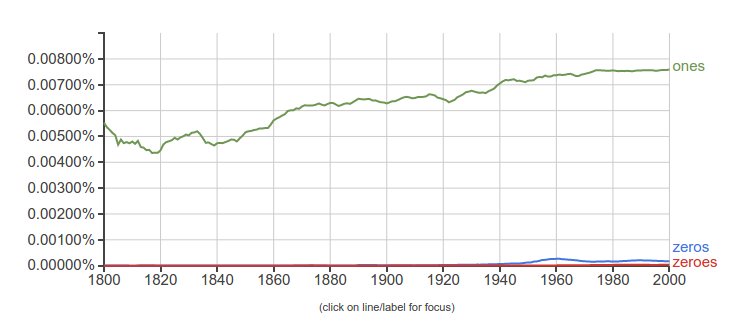
Not that I’d ever be fooled by that …
